
文字コードの話は難しそうなイメージがあり、必要になったタイミングでその都度、最小限の知識を習得して対応してきました…が、効率が悪く踏み込んだ話になった時に困る場合もあるので、ここで真面目に整理しようと思いました。
はじめに
- 私の経験上、Windowsユーザを想定したアプリ開発が多いため、Windows環境で使用されるWindows-31Jを主とした話となります。
- Windows-31Jと直接関係のないJIS X 0213、Shift_JISX0213やShift_JIS2004の説明は割愛しています。
- ネット上のWiki等の情報を独自に纏めた内容になっており、間違っている可能性もあります。別のソース等を参考にして正確性を担保することを推奨します。
- Unicodeコードポイント、UTF-8/16/32とサロゲートペア、C言語サンプル等の説明をこちらで紹介しています。
符号化文字集合と文字符号化方式
文字コードの話の冒頭で出てくる重要なポイントとなる用語です。
扱う文字の一覧の定義(符号化文字集合)と、それをどのようにバイト列化するかの規則・ルール(文字符号化方式)です。
この2つの違いが曖昧だと、用語の整理が難しくなり、理解が進まなくなります…「符号化文字集合」「文字符号化方式」という単語を覚える必要はありませんが、今後出てくる用語がどちらの分類の物なのかを意識することが重要だと思います。
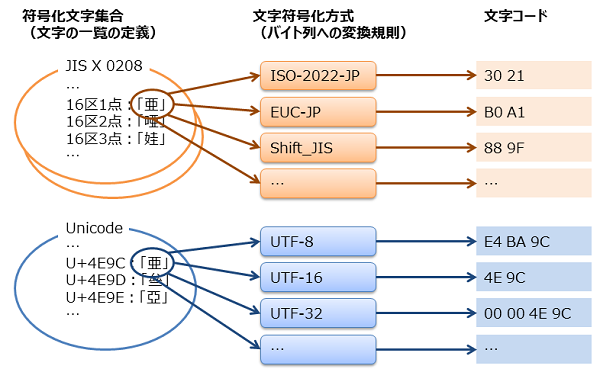
- 符号化文字集合
- PC等のデータ処理やデータ交換を行うシステムで利用できる文字一覧のこと。
- 日本語の場合、次のようにJIS(日本の標準)として定義されている。
文字の種類や使用頻度(人名や行政地名等)に応じて、水準分けされている。規格名 収録文字 JIS X 0201(旧JIS C 6220) 半角の英数記号、半角カナ JIS X 0208(旧JIS C 6221) 非漢字、第1水準、第2水準 JIS X 0213 非漢字、第1水準、第2水準、第3水準、第4水準 - JIS X 0208の場合、対象の文字を94×94の表で定義している。縦軸は「区」、横軸は「点」と呼び、文字位置(区点位置)を区点番号で表現する。
例えば、文字「亜」の区点番号は「16区1点」と表現する。
なお、JIS X 0213では、94×94の表を「面」と定義し、複数の「面」持つよう変更されている。 - 仕様検討等で許容文字を表現する場合、符号化文字集合の用語がよく使用される。
JIS X 0208/0213への対応有無、非漢字/第1水準/第2水準の許容有無、区点位置における区の指定による範囲指定等。
- 文字符号化方式(エンコーディング)
- 符号化文字集合で定義された文字を、データ処理システムで扱えるデータに変換する規則のこと。
- JIS X 0201/0208に対応する文字符号化方式を次に示す。
文字符号化方式 説明 ISO-2022-JP 主に電子メール(件名等)で使用される。JISコードとも呼ばれる。 EUC-JP 主にUNIX/Linux系で使用される。
多言語に対応できるようEUCが定められ、その日本語版がEUC-JPである。Shift_JIS 主にWindows系で使用される。MacOS 7~9でも使用された。
(Windowsの場合はShift_JISをベースにしたWindows-31J、Macの場合はShift_JISをベースにしたMacJapanese) - ある文字を異なる文字符号化方式で符号化すると、異なる値(バイト列)になる。
例えばJIS X 0208の文字「亜」は、ISO-2202-JPでは”30 21″、Shift_JISでは”88 9F”になる。
Unicodeの文字「亜」は、UTF-8では”E4 BA 9C”、UTF-32では”4E 9C”になる。 - 文字符号化方式が決まらないと設計や実装で扱う文字コードを確定できない。そのため、設計書の最初に使用する文字符号化方式を決定した上で、その方式での文字範囲を決定する必要がある。
- UnicodeとUTF-8/UTF-16/UTF-32、サロゲートペア等の概要に関しては、こちらで説明しています。
- エンコーディングと実際のバイト列の関係は、こちらのオンラインツールで確認できます。


Windows-31Jが策定されるまでの経緯
JIS X 0201/0208(旧JIS C 6220/6226)の規格化、文字符号化方式としてのShift_JISの策定、ベンダ間での協議を経たWindows-31Jの策定、までの経緯を次に示します。(図中の緑枠ボックス)
この経緯を理解することで、Windows-31Jがベースにしている規格や対応する・しない漢字水準を理解することができます。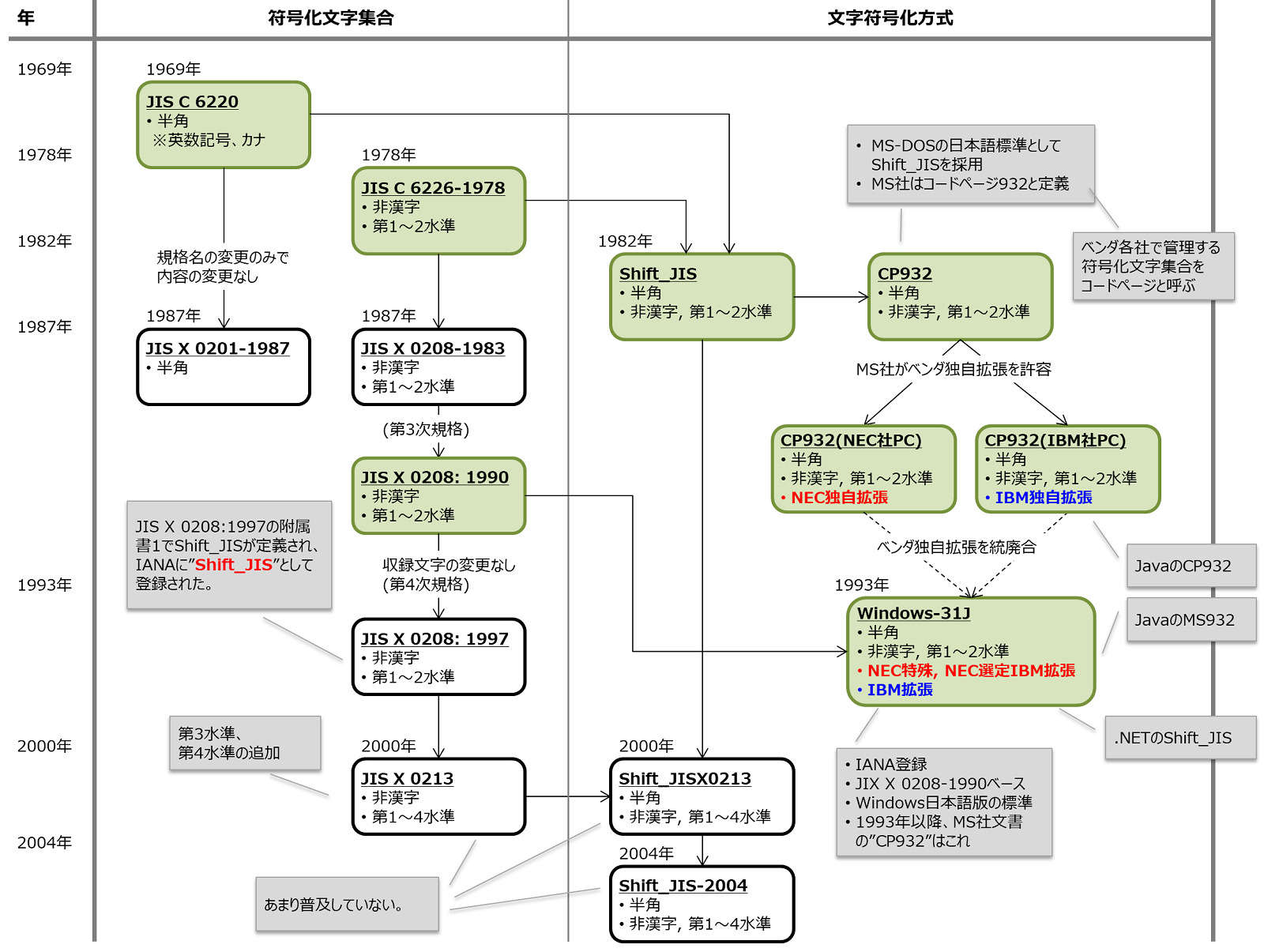
- 1982年にShift_JISが策定され、マイクロソフト社はMS-DOSにおける日本語の文字符号化方式としてShift_JISを採用した。
- マイクロソフト社では、これをCP932と呼んで管理した。(ベンダ独自の文字符号化方式の定義をコードページCPと呼び、マイクロソフトやIBMはそれぞれ独自のコードページを定義している。)
- Shift_JISは正式な標準化はもう少し後で、JIS X0208:1997の附属書1で正式に定義された。この内容が、”Shift_JIS“としてIANAに登録された。
- マイクロソフト社はCP932に対するベンダ独自の拡張を許容したため、当時の主流であったNEC社のPC-9800、IBMのPS/55、富士通のFMRシリーズでは、CP932に対して独自の文字の追加を行った。
(JIS X 0208の規格としては94区まで使用しているが、各ベンダは94区以内外の未使用の区に独自の文字を定義した。) - 1993年、マイクロソフト社はWindows 3.1日本語版を公開するにあたり、CP932の見直しを行ったWindows-31Jを策定した。
- Windows-31Jは、最新の日本語のJIS規格であるJIS X 0208-1990をベースとし、特に大きなシェアを持つNECとIBMの2社で独自拡張していた文字コードを統廃合して追加した。
- ベンダ独自の拡張を禁止した。
- IANAに登録したことで、Windows-31Jはインターネット標準の名称となった。
Shift_JISとWindows-31Jの違い
Shift_JISにNEC/IBM拡張文字コードを追加したものがWindows-31Jである。
両者の違いは、NEC/IBM拡張文字コードの有無である。
- 前述の経緯の図では、Windows-31JでベースになったのはJIS X 0208: 1990、Shift_JISとして登録されたのはJIS X 0208: 1997である。
- JIS X 0208: 1990とJIS X 0208: 1997で収録文字の違いはないので、JIS X 0208: 1990とJIS X 0208: 1997(Shift_JIS)は実質同じ内容となる。
(JIS X 0208: 1997は、JIS X 0208: 1990の収録文字を変更せずに規格票を大幅に更新した内容になっている。第4次規格を参考のこと。) - 後述するが、Shift_JISという言葉が曖昧に使われる場合があるので注意が必要である。
- 担当者が「Windowsで使われているShift_JIS」という意図で話している場合、Shift_JIS=Windows-31Jである。
- .NET系ライブラリで指定できる”Shift_JIS”は”Windows-31J”です。
Shift_JISとWindows-31Jの文字対応
Shift_JIS/Windows-31Jの非漢字/第1水準/第2水準、Windows-31J固有の拡張文字群は、次のように区点コード(区)で範囲が指定されてされています。
| 分類 | JISの区 (開始 – 終了区) | Shift_JIS/Windows-31Jコード (開始区1点 – 終了区94点) | 備考 |
|---|---|---|---|
| 非漢字 | 01 – 08 | 0x8140 – 0x84fc | |
| 記号 | 01 – 02 | 0x8140 – 0x81fc | |
| 数字、英大小文字 | 03 | 0x8240 – 0x829e | |
| ひらがな | 04 | 0x829f – 0x82cf | |
| カタカナ | 05 | 0x8340 – 0x839e | |
| ギリシア文字 | 06 | 0x839f – 0x83fc | |
| キリル文字 | 07 | 0x8440 – 0x849e | |
| 罫線 | 08 | 0x849f – 0x84fc | |
| NEC特殊 | 13 | 0x8740 – 0x879e | ①, ㍍, ㈱ 等。 |
| 第1水準 | 16 – 47 | 0x889f – 0x989e | |
| 第2水準 | 48 – 84 | 0x989f – 0xeafc | |
| NEC選定IBM拡張 | 89 – 92 | 0xed40 – 0xeefc | Windowsでは実質未使用。 |
| ユーザー定義外字 | 95 – 114 | 0xf040 – 0xf9fc | Windows-31Jで未定義、参考として掲載 |
| IBM拡張 | 115 – 119 | 0xfa40 – 0xfc9e | 﨑, 髙等。 |
- 上記のWindows-31Jのコード値は、区の範囲の定義(開始区1点から終了区の94点)に基づいて算出した。
- NEC特殊、NEC選定IBM拡張、IBM拡張はShift_JISを拡張した領域で、Windows-31J独自の領域である。(図中の水色行)
- NEC選定IBM拡張の文字は、JIS/NEC特殊/IBM拡張と重複している。WindowsのAPIでは、文字の入力や変換時、NEC選定IBM拡張以外に文字を対応付けるため、NEC選定IBM拡張はWindowsでは実質使用されていない。
- Windows-31Jではユーザ定義外字領域(独自の文字を定義可)を定義していないが、Windowsでは外字領域として使用できるため、参考として記載した。(図中の灰色行)
- Windowsでの外字の定義や領域の確認は、[コントロールパネル]の[外字エディター]で可。
要件や仕様確定のためのポイント
経験的に、要件や仕様を取り纏める側と設計・実装を行う側で「分かった気」になって検討が進み、設計の詳細化や実装時になって曖昧さに気づくことが多いです。結果として、仕様変更や実装の見直しが発生し、作業が遅延することが多いです。
次のポイントを押さえた要件・仕様の明確化や設計の詳細化を推奨します。
- 基礎の理解
- まず、符号化文字集合と符号化方式に分けられることを理解する必要がある。
- 符号化文字集合の代表はJIS C/JIS X等のJIS規格。
JIS X 0208は非漢字、第1水準、第2水準を収録する。Shift_JISやWindows-31Jのベースになっているもので使用頻度が高く覚えておきたい。
JIS X 0213は第3水準、第4水準を収録する最新の規格であるが、Shift_JISやWindows-31Jに含まれず、ほとんど普及していないため忘れても構わないかも。 - 符号化方式はShift-JIS, Windows-31J, JIS, EUCなど
- 業務要件・仕様の正確な理解
- Shift-JIS、SJISという言葉が使われた場合、本来のShift_JISの話なのか、Windows-31Jの話なのかを明確にする必要がある。
Windowsユーザからの入力を想定している場合はWindows-31Jを意図している場合が多い。ホスト系や外部システムとの連携を想定している場合、本来のShift_JISを意図していることもある。 - 許容する文字範囲を指定する際、主に符号化文字集合の用語が使用される。
JIS X 0208(非漢字、第1~2水準)、JIS X 0213(非漢字、第1~4水準)など。 - Windows-31Jを扱う場合、文字範囲として、NEC特殊文字、NEC選定IBM文字、IBM特殊文字が指定される場合もある。
- JIS X 0201に関しては半角系の文字で、暗黙的にJIS X 0208/0213に含めて話している場合が多い。
- Shift_JIS、Windows-31Jは1文字は1バイトまたは2バイトになる。UTF-8等の別の文字符号化方式では可変長バイトになる場合があることに注意。
- 外字領域は環境依存するため、基本的には利用禁止にすることが多い。
- Shift-JIS、SJISという言葉が使われた場合、本来のShift_JISの話なのか、Windows-31Jの話なのかを明確にする必要がある。
- 処理系でのエンコーディングの理解
- 処理系によって文字符号化方式の名称の解釈が異なる場合がある。指定した名称によって実際にどのような文字符号化方式が使用されるのかリファレンスで確認する必要がある。
- .NETでエンコーダを取得するためにEncoding.GetEncoding(“Shift_JIS”)とすると、実際にはWindows-31J(CodePage932)のエンコーダが取得される。
- JavaでWindows-31Jを指定する場合、MS932やWindows-31Jを指定する必要がある。CP932を指定するとIBM社拡張のCP932が使用される。
参考
この記事を作成するにあたり、次のサイトを参考にしました。
- 文字符号化方式 – Wikipedia
- JIS X 0201 – Wikipedia
- JIS X 0208 – Wikipedia
- Shift_JIS – Wikipedia
- Microsoftコードページ932 – Wikipedia